Data warehouse (DW or DWH), also known as enterprise data warehouse (EDW), is a place that integrates data sources for some specific purpose. Since this note is written after self-learning in two days only, I will appreciate to adopt your advice if there is any defect or inaccuracy.
Data warehouse
With data being generated in overwhelming amounts today, it’s necessary to design a storage structure that make the query efficiently for different requirements. To explain the difference between the databases and data warehouse, we first discuss the following terminologies:
| On-line transaction processing (OLTP) | On-line analytical processing (OLAP) |
|---|---|
| low-end operation | high-end analysis |
| real-time | long-term |
| small (GB) | large (TB) |
| resemble operational data store (ODS) | - |
| databases, files | data warehouse |
| MySQL, MariaDB, MongoDB | AWS |
We can easily see that the common database is for collecting the frontline data, that must support efficient insertion, deletion, modification, etc. i.e. The transaction data, the ordering data, the signal data of equipment. On the contrary, we need to manage the data from different sources so that we can query them in a specific, easy and efficient way for long-term analysis.
The standarization of dealing with data, so-called data pipeline is shown as below:
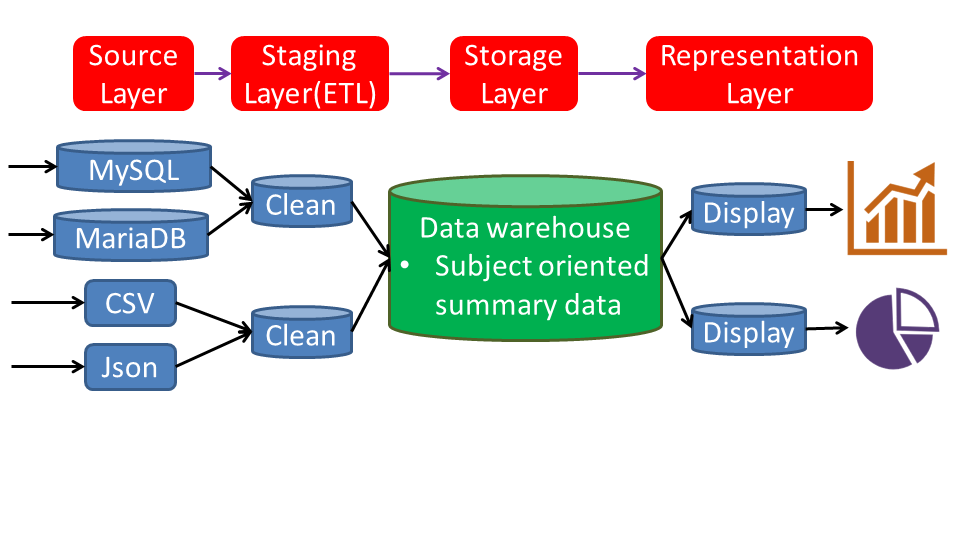
There are four stages (layers) for managing the large amount of data. The first is the source layer, which collects real-time data in databases or files in different forms. The next step is the staging layer, also well-known as ETL (extract-transform-load). To make access data more efficiently, the data must be well-preproccessed before insert into the data warehouse. The process for a huge system is exceeding complicate. Hence, some software for ETL is recommended. The design of data structure of the storage layer plays the most important role in the data pipeline due to the efficency of extracting data to dash board in the presentation layer. Let’s start it now.
Star schema
The star schema is the simplest way to model data warehouse systems. The center of the star can have one fact table and a number of associated dimension tables. The shape of their connections resembles a star.
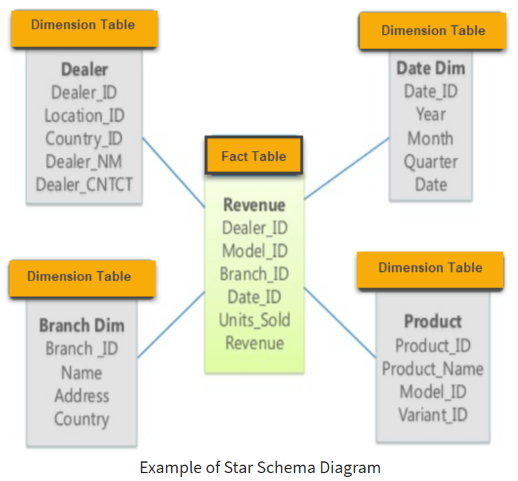
The fact table records the measurements, metrics or facts about a business process, such as a transaction table. It is simple without hierarchy data. The grain, so-called granularity, refers to the size in which data fields are sub-divided. It determines the detail records in the fact table. For example, an address can be
1 | "address=200 2nd Ave. South #358, St. Petersburg, FL 33701-4313 USA" |
or with fine granularity:
1 | street address = 200 2nd Ave. South #358 |
The dimensional table stores the descriptive data, i.e. date, branch, product. The columns of fact table reference the foreign key to each dimensional tables and the combinations of the foreign keys is the primary key of the fact table. The structure ensures that there is no duplicated data in fact table and forbid to insert data which contains key doesn’t exist in certain dimensional table. Likewise, to prevent the repeating data in the dimensional table, we need a column for indexing. In general, if the raw data contains the primary key of a column, it is called natural key or business key. However, it is not suitable to used it as primary key if the records is much less than the corresponding size of the hash table. For instance, the ID number is natural key due to its uniqueness, but if there are several hundreds of people only, the degits of ID number spans so large hash table that extremely waste the memory space. An alternative is to add a smaller size column without meaning called surrogate key. The dimensional tables can be normalized as hierarchy structure and the relations become snowflake schema.
Distributed system
The big data, is the large amount of data that cannot load into a single computer. That is, the techniques to manage the distributed data. There are many open sources software to setup the environment such as the NoSQL database MongoDB, and the distributed system Hadoop or Spark. However, I have spent lots of time so far and run out of time now. so catch you later. The other terminologies:
- HDFS
- data virtualization
- poly base
- data vault
Reference
- https://datawarehouseinfo.com/data-warehouse-architecture/
- https://en.wikipedia.org/wiki/Extract,_transform,_load
- https://www.holistics.io/blog/data-lake-vs-data-warehouse-vs-data-mart/
- https://social.technet.microsoft.com/Forums/en-US/0c946b78-fd1f-4207-9f7b-c5eb0081f509/what-is-business-key?forum=sqldatawarehousing
- https://www.guru99.com/fact-table-vs-dimension-table.html
- https://www.guru99.com/star-snowflake-data-warehousing.html
- https://blog.tibame.com/?p=1752
- https://en.wikipedia.org/wiki/Granularity